
Today I’m going to show you how you leverage the internal site search report from Google Analytics to automatically suggest mappings to category pages using Python and the popular Polyfuzz library.
Selectively mapping internal searches directly to category pages makes for a good user experience because it takes users directly to the page they were looking for.
The script works by mapping keywords from the internal site search report to ‘H1s’ from a crawl file. It uses the Polyfuzz library to fuzz match keywords to category ‘H1s’. Fuzzy matching allows matching to plurals, close matches and words found in a different order.
This article will walk you through the code. It also includes a link to the source code on GitHub, as well as a Google Colab Notebook for ease of use.
The Problem We’re Trying to Solve
This eCommerce site returns a list of matching products when a user searches for ‘LED Lights’.
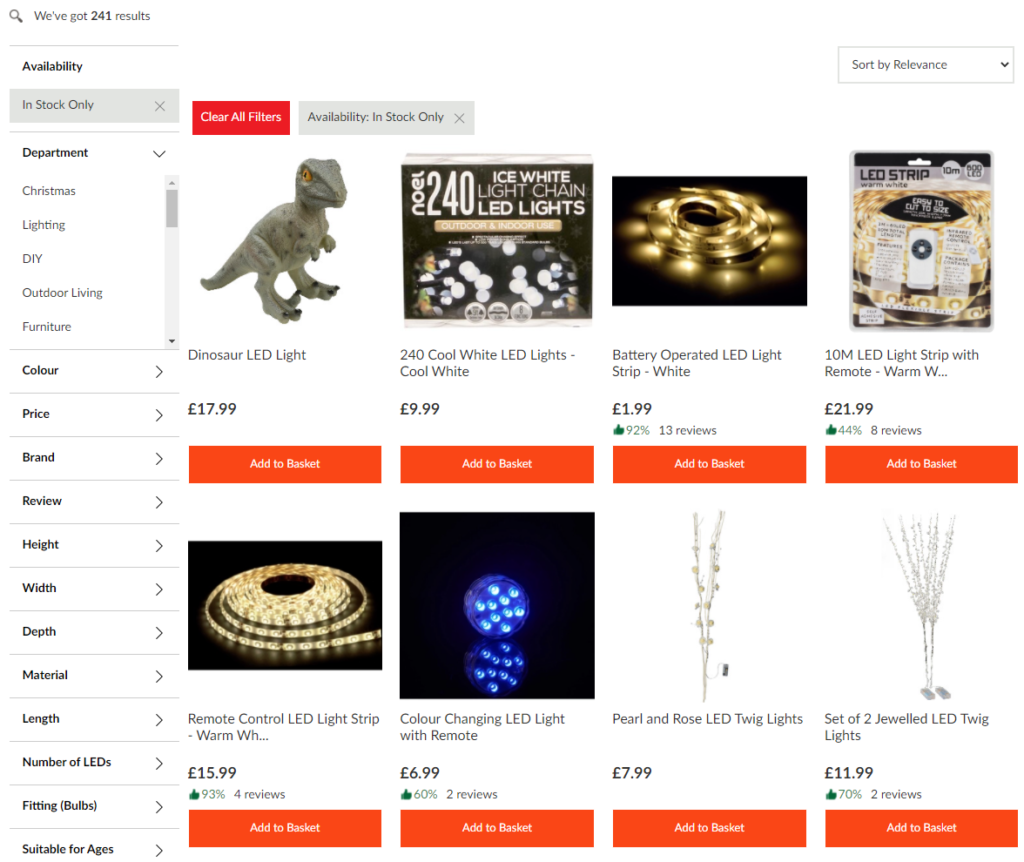
This is not necessarily bad per say, but a much better solution would be to take the user directly to the Led Lighting category instead…
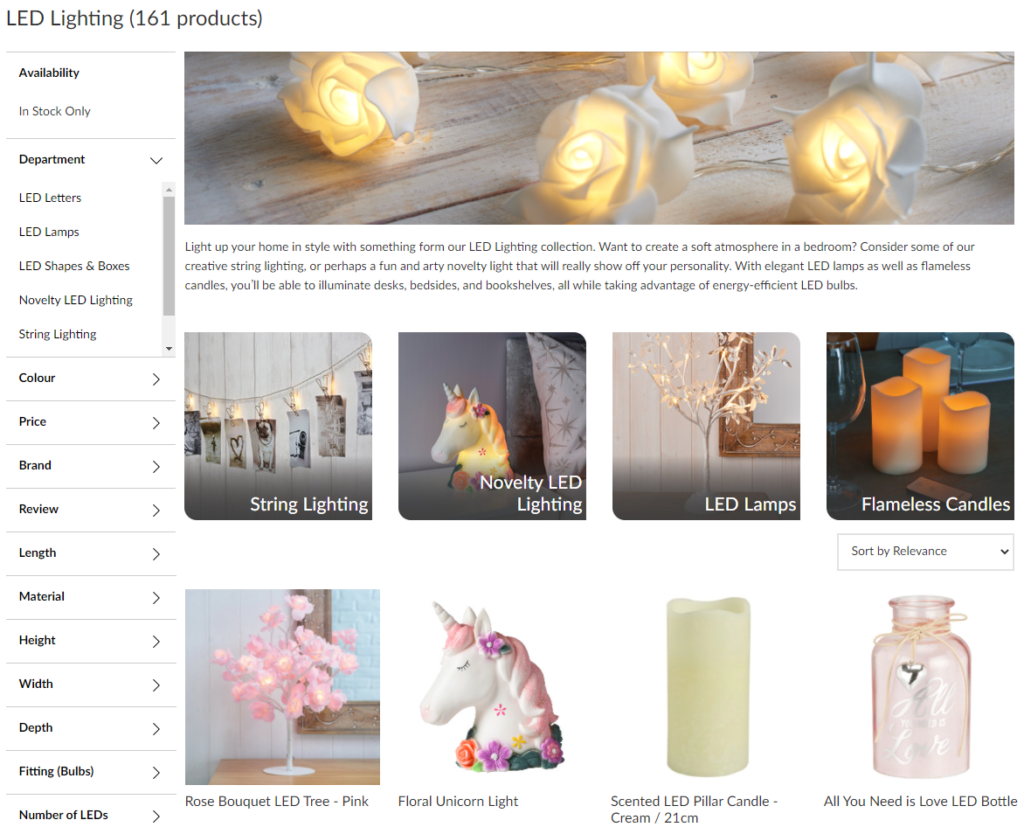
Benefits of taking users directly to a matching category page:
- Additional subcategories for the user to drill down into
- Focused category copy showcasing features, benefits and range highlights
- Focused first page product selection
Input Files Required
- Site search report from Google Analytics (Excel format only)
- Internal_html report from Screaming Frog (CSV format only)
Getting The Files: Site Search Report (Google Analytics)
The site search report is accessed via Behaviour > Site Search > Search Terms
- Set a sensible date range to export (three months is usually ideal, setting it too far back runs the risk of stale data for dead stock etc).
- Change the number of rows to the maximum available (or less if you prefer).
3. Finally, export the file in Excel format.
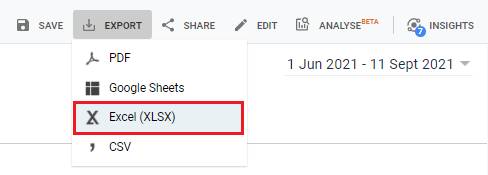
Getting The Files: Internal_html (Screaming Frog)
The Screaming Frog export is really straight forward. You just need to export the internal html as a .csv file as shown below.
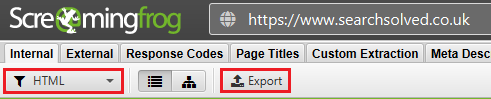
Script Output
The script outputs three different CSV files. All matches (contains partial and exact matches), all matches or partial matches.

The final output shows the search term from Google Analytics in column A, fuzzy matched to a category H1 from the crawl file. note some words are matched 100% even if they appear out of order.
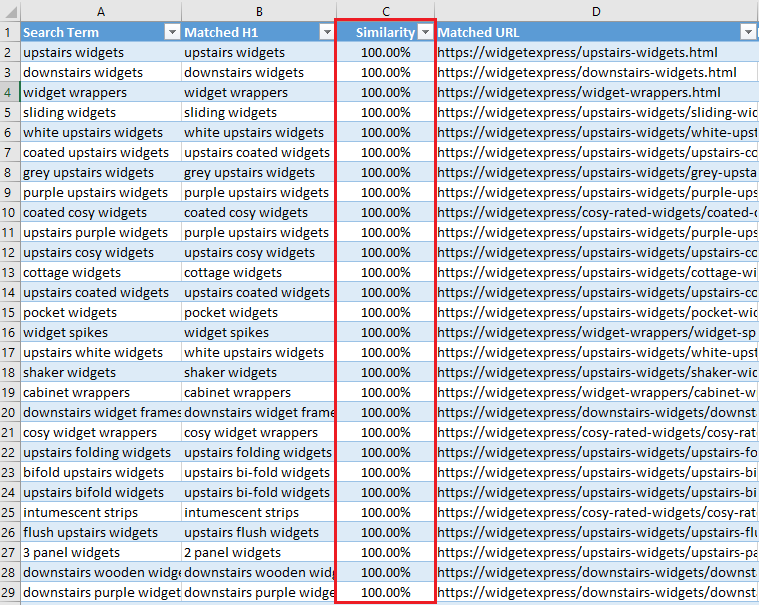
Script Walkthrough
First we need to install pandas and the Polyfuzz library if not already installed.
pip install pandas
pip install polyfuzz
Do the imports.
from polyfuzz import PolyFuzz
from glob import glob
import pandas as pd
Set the folder paths for the site search report and the crawl export.
# set the folder paths HERE for your input files!
ga_path = "C:\python_scripts\Internal Search Mapper" # enter the path the the folder that contains your GA search terms export
sf_path = "C:\python_scripts\Internal Search Mapper" # enter the path of the folder that contains internal_html.csv file
export_path = "C:\python_scripts\Internal Search Mapper" # enter the path to export the output.csv file to
This code appends the file names to the paths set above.
# adds file names to the paths.
ga_path_file = ga_path + "/Analytics*.xlsx"
sf_path_file = sf_path + "/internal_html.csv"
export_exact = export_path + "/search-mapping-exact-matches.csv"
export_partial = export_path + "/search-mapping-partial-matches.csv"
export_all = export_path + "/search-mapping-all-matches.csv"
Imports the internal site search report from Google Analytics. NB: File must be in Excel format.
# imports GA data using a wildcard match
for f in glob(ga_path_file):
df_ga = pd.read_excel((f), sheet_name="Dataset1")
Read in the Screaming Frog crawl. (I recommend removing any page you don’t want to map the internal site search report to. (e.g. remove product pages, if you dont’ want to map searches there.
df_sf = pd.read_csv(sf_path_file, encoding="utf8")[["H1-1", "Address", "Indexability"]]
Drop the H1 and internal site search report keywords to lower case for matching a deduping.
# convert to lower case for matching
df_sf["H1-1"] = df_sf["H1-1"].str.lower()
df_ga["Search Term"] = df_ga["Search Term"].str.lower() # convert to lower case for matching
Try to drop non-indexable pages. (‘Indexability’ must be ticked in the ‘Extraction’ heading of Screaming Frog settings.
# drop non-indexable pages
try:
df_sf = df_sf[~df_sf["Indexability"].isin(["Non-Indexable"])]
except Exception:
pass
Clean up the dataframe by deleting the helper columns and remove any NaN values.
# delete the helper column
del df_sf["Indexability"]
# keep rows which are not NaN
df_ga = df_ga[df_ga["Search Term"].notna()]
df_sf = df_sf[df_sf["H1-1"].notna()]
Create two lists, one from the internal site search report, and another from the Screaming Frog crawl, ready to be fuzzy matches using Polyfuzz.
# create lists from dfs
ga_list = list(df_ga["Search Term"])
sf_list = list(df_sf["H1-1"])
It’s time to match the two lists using Polyfuzz!
# instantiate PolyFuzz model, choose TF-IDF as the similarity measure and match the two lists.
model = PolyFuzz("TF-IDF").match(ga_list, sf_list)
# make the polyfuzz dataframe
df_pf_matches = model.get_matches()
# keep only rows which are not NaN
df_pf_matches = df_pf_matches[df_pf_matches["To"].notna()]
Let’s merge the GA data back into the dataframe Polyfuzz created.
# merge original ga search term data back into polyfuzz df
df_pf_matches_df_ga = pd.merge(df_pf_matches, df_ga, left_on="From", right_on="Search Term", how="inner")
# create final_df + merge original screaming frog data back in
final_df = pd.merge(df_pf_matches_df_ga, df_sf, left_on="To", right_on="H1-1")
Let’s clean and sort the dataframe some more.
# sort by opportunity
final_df = final_df.sort_values(by="Total Unique Searches", ascending=False)
# Round Float to two decimal places
final_df = final_df.round(decimals=2)
# rename the cols
final_df.rename(columns={"From": "Search Term", "To": "Matched H1", "Address": "Matched URL"}, inplace=True)
# set new column order for final df
cols = [
"Search Term",
"Matched H1",
"Similarity",
"Matched URL",
"Total Unique Searches",
"Results Page Views/Search",
"% Search Exits",
"% Search Refinements",
"Time After Search",
"Avg. Search Depth",
]
# re-index columns into a logical order
final_df = final_df.reindex(columns=cols)
# drop duplicate keywords
final_df.drop_duplicates(subset=["Search Term"], inplace=True)
Time to export the final CSV files.
# export the final csv
final_df_exact = final_df.loc[final_df["Similarity"] == 1]
final_df_partial = final_df.loc[final_df["Similarity"] != 1].copy()
final_df_partial.sort_values(["Similarity", "Total Unique Searches"], ascending=[False, False], inplace=True)
final_df_exact.to_csv(export_exact, index=False)
final_df_partial.to_csv(export_partial, index=False)
final_df.to_csv(export_all, index=False)
Done! The script outputs three different files; Partial matches, exact matches and both match types combined.
Link to Github / Google Colab
Listed below are links to GitHub so you can play with the finished code. I’ve also included a Google Colaboratory Notebook which is even easier to use. (Just upload the crawl file and internal site search report from Google Analytics and the script will do it’s magic!)
Link to GitHub
Link to the Google Colaboratory Notebook
Let me know how you get on by tweeting me @LeeFootSEO


